deployment
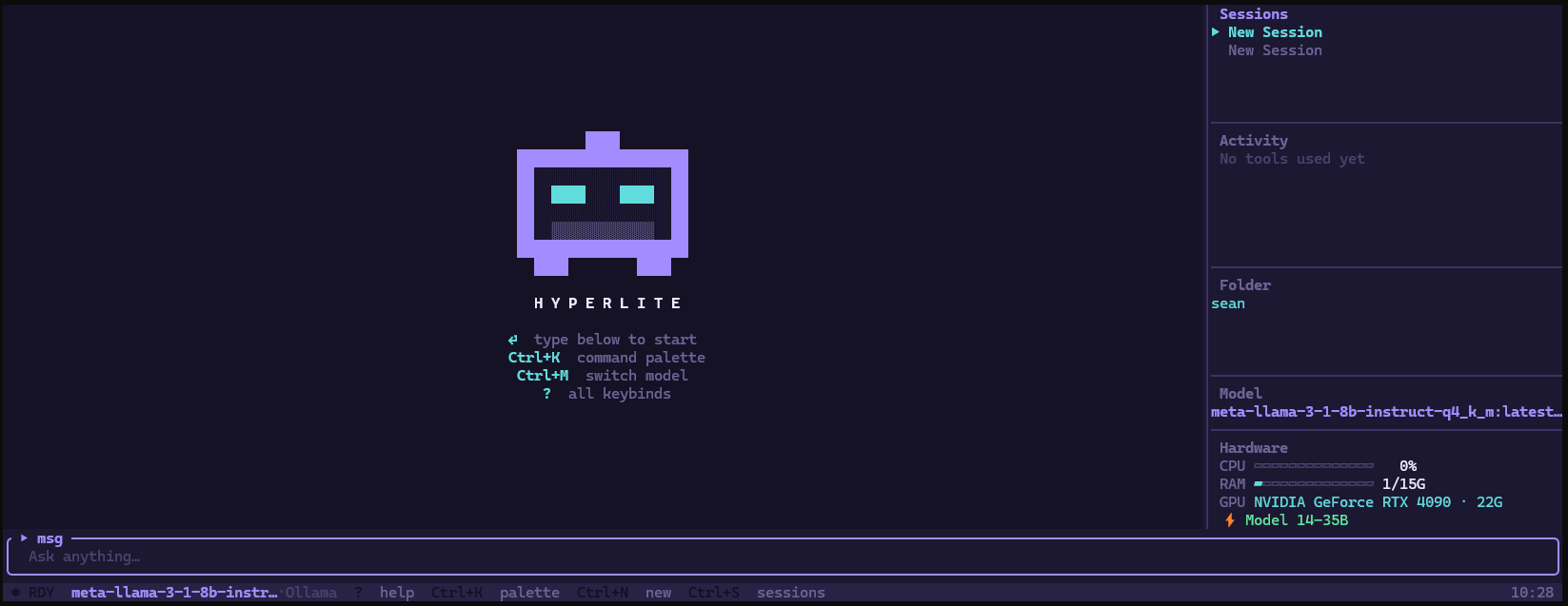
One binary. No runtime. No setup.
HyperLite ships as a single statically-linked binary — hl. No Python environment. No Node.js. No Docker. No daemon running in the background. Copy it to any machine and it runs.
The entire application — TUI, inference routing, tool execution, RAG, memory, streaming — is ~35 MB on disk.
inference
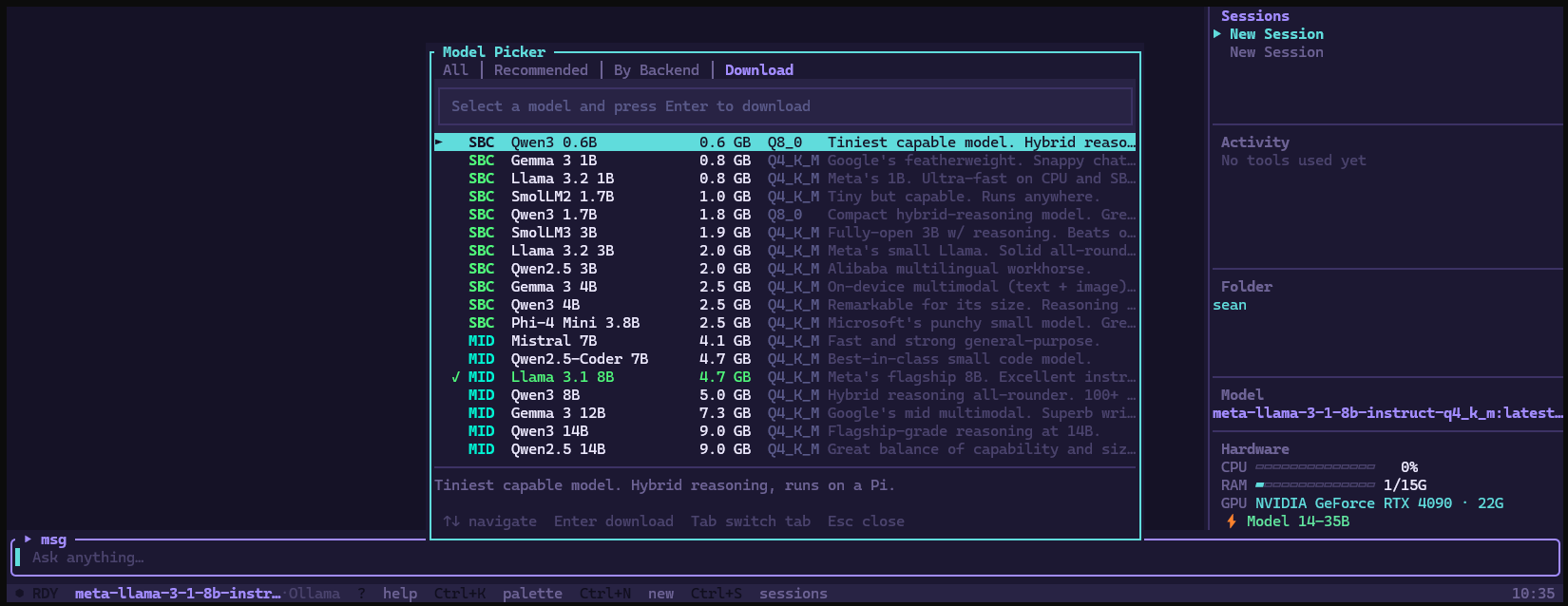
Works with any backend. Switching is free.
A unified provider layer speaks to Ollama, llama-server, LM Studio, Jan, GPT4All, KoboldCpp, LocalAI, vLLM, and TextGen WebUI through one interface. Switching backends is a model selection — nothing else changes. The same conversation continues, the same tools work, the same agents run.
When Ollama is present it takes priority for GPU acceleration. When it's not, HyperLite spawns llama-server with parameters derived from your actual hardware — VRAM, core count, architecture — not hardcoded defaults.
tool_system
The agentic loop runs on any model.
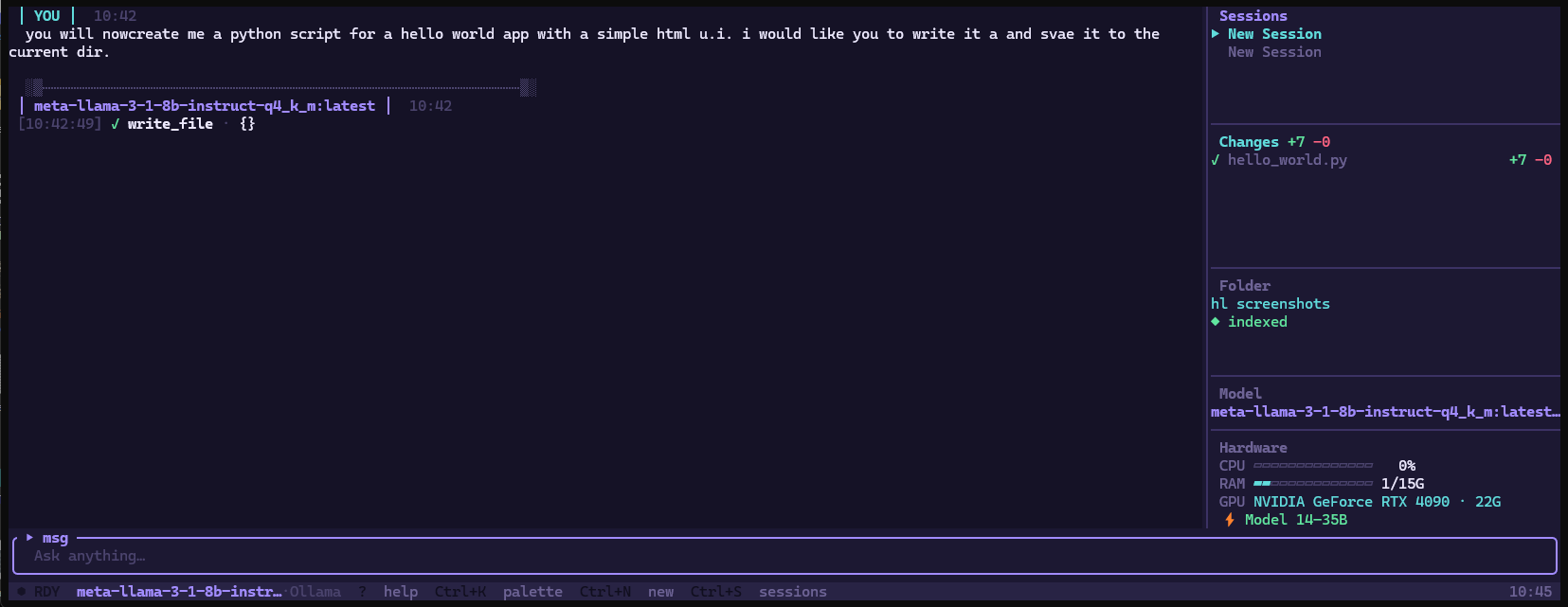
Native function calling (OpenAI tool-use format) requires specific model support. HyperLite's tool system doesn't. It parses <tool_call> XML blocks from any model's output in real-time during streaming, executes the tool, and feeds the result back.
The result: file reads, writes, shell execution, web search, git operations — all 39 tools — work with SmolLM 1.7B the same way they work with a 70B model. The model's capability determines quality. The architecture doesn't impose a ceiling.
writes
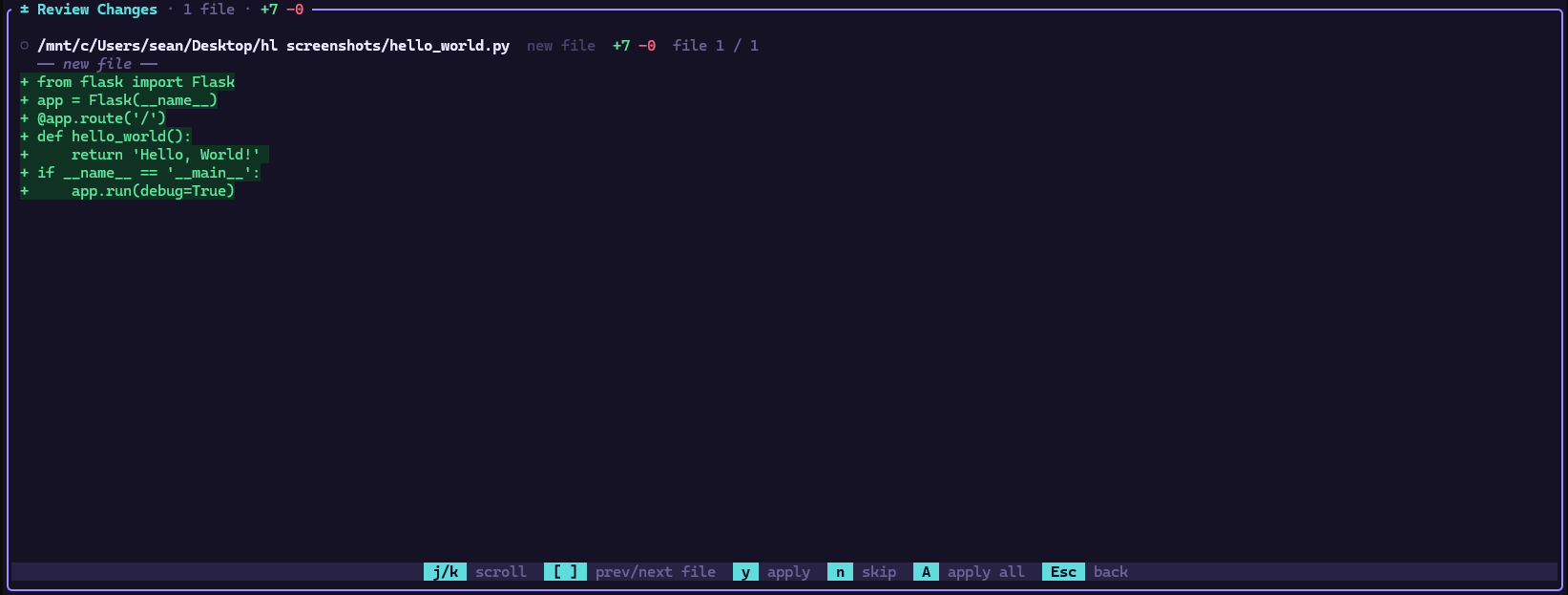
File writes require approval. By design.
Every file write is intercepted before hitting disk. The proposed change renders as a syntax-highlighted diff — green for additions, red for deletions — with the confirmation prompt appearing after all content so you read before you decide.
This isn't a setting. It's the architecture. The tool dispatcher routes write_file and edit_file through a pending diff queue before execution. Approve or discard. The AI never writes without explicit confirmation.
data
Local-first. All the way down.
No telemetry. No API keys required. No cloud. Every piece of the stack runs on your machine: inference on your GPU, semantic search via local ONNX embeddings indexed into SQLite, conversation history in SQLite — session-branching capable, never leaves your machine.
The only outbound requests are ones you explicitly trigger: web search, http_fetch, model downloads from HuggingFace. Everything else is air-gapped by default.
context
Context sized to your hardware. Not a default.
The context window is calculated at startup from real hardware detection — not a hardcoded value. A 24 GB GPU gets 32 768 tokens. A 10 GB card gets 16 384. The system reads what you have and configures accordingly, per-request.
When you switch models mid-conversation, HyperLite compacts the full history using the current model before handing off — a clean factual summary the new model can work from without confusion.